Large Language Model (LLM)¶
A Large Language Model (LLM) is a type of artificial intelligence model designed to understand and generate human-like text by learning patterns in vast amounts of language data. Built using deep neural networks—typically transformer architectures—LLMs are trained on billions of words and contain millions to hundreds of billions of parameters. These models can perform a wide range of natural language processing tasks such as answering questions, writing code, summarizing documents, translating languages, and engaging in conversation.
Closed-source vs Proprietary LLM¶
Closed-source LLMs are proprietary models developed and maintained by companies that do not release their underlying code, training data, or model weights to the public. Access to these models is typically provided through paid APIs (e.g., OpenAI's GPT-4, Google's Gemini, Anthropic's Claude, xAI Grok), offering high performance but limited transparency and customization.
In contrast, open-source LLMs—such as Meta's LLaMA, Mistral, and Falcon—release their model weights (and sometimes training code and datasets), allowing researchers and developers to run, fine-tune, and modify the models freely. Open-source LLMs promote transparency, innovation, and local deployment but may require more technical expertise and computing resources to use effectively.
LLM Training Cost¶
Creating LLMs is an extremely resource-intensive process, involving massive datasets, vast computational power, and highly specialized expertise. Training a modern LLM from scratch can cost millions to tens of millions of dollars, depending on the model size, training time (weeks to months), and engineering and infrastructure costs. For example, GPT-3 (175B) reportedly cost $5–10 million to train. Training LLMs requires high-performance GPUs or AI accelerators. A single LLM training run may use thousands of GPUs (in parallel across many servers), petabytes of storage, terabytes of RAM, and high-speed interconnects (e.g., NVIDIA NVLink, Infiniband).
LLM Parameter Size¶
In the context of LLMs, model parameter size refers to the number of trainable weights in the model. Each parameter is a part of the neural network responsible for learning from data and influencing the model’s output. For example 110M means 110 million parameters or 7B mean 7 billion parameters. Generally, a higher number of parameters means the model can learn more complex patterns and produce more accurate, fluent, and nuanced outputs. Larger models tend to perform better. However, larger models require more hardware, consume more energy, are slower to run, and take more storage. Thus, large models may be overkill for simple tasks like classification or basic summarization.
GPU VRAM¶
Running an LLM involves billions of matrix operations across multiple layers of the network. This workload is accelerated significantly using GPUs due to their massive parallelism. GPU VRAM is crucial here. VRAM (Video Random Access Memory) is the dedicated memory on a GPU that serves a similar role to system RAM but is optimized for the high-throughput demands of parallel processing and graphical workloads. The entire model (weights, optimizer states) must fit into VRAM during inference. For example, a 7B model typically requires ~6–12 GB VRAM, depending on quantization type being used. When everything fits in VRAM, there is no need to swap data between system RAM and GPU memory, which avoids bottlenecks.
Quantization in LLMs¶
Quantization is a technique used to reduce the memory footprint and computational load of a LLM model by representing its numerical weights and activations with lower precision—typically using 8-bit or 4-bit integers instead of the standard 16-bit or 32-bit floating-point values. This compression allows LLMs to run efficiently on consumer hardware with limited VRAM while maintaining most of their original accuracy.
| Quantization Type | Bit Width | Description | Accuracy Impact | File Size Reduction | VRAM Usage |
|---|---|---|---|---|---|
| FP32 | 32-bit | Full precision float | None | None | Very High |
| FP16 / BF16 | 16-bit | Half precision float (common for training/inference) | Minimal | ~2× smaller than FP32 | High |
| INT8 | 8-bit | Integer quantization with calibration | Low | ~4× smaller | Moderate |
| Q8_0 | 8-bit | Quantized weights only, no groups/scales | Very Low | ~4× smaller | Moderate |
| Q6_K | 6-bit | 6-bit group quantization | Moderate | ~5× smaller | Lower |
| Q5_0 / Q5_K | 5-bit | 5-bit quantization with (K) or without (0) grouping | Moderate | ~6× smaller | Lower |
| Q4_0 / Q4_K | 4-bit | Basic (0) or grouped (K) 4-bit quantization | Medium | ~8× smaller | Low |
| Q4_K_M | 4-bit | Grouped + matrix-optimized 4-bit quantization | Low–Moderate | ~8× smaller | Low |
| GPTQ | 4–8 bit | Layer-aware quantization with optional calibration | Minimal–Moderate | 4–8× smaller | Low |
| AWQ | 4–8 bit | Activation-aware weight quantization | Minimal | 4–8× smaller | Low |
| GGUF | 2–8 bit | Format that includes metadata + quantized weights | Depends on mode | 4–10× smaller | Very Low |
NVIDIA GPUs¶
NVIDIA is a technology company best known for designing and manufacturing high-performance GPUs. While it initially rose to prominence in the gaming industry with its GeForce GPU line, NVIDIA has since expanded its reach into data centers, AI, autonomous vehicles, and high-performance computing (HPC). It provides both the hardware (e.g., A100, H100, and RTX GPUs) and the software ecosystem (e.g., CUDA, cuDNN, TensorRT) that power everything from 3D rendering to deep learning workloads.
NVIDIA became hugely popular in the LLM space due to the nature of LLM training and inference, which requires performing massive matrix and tensor operations—tasks that GPUs are uniquely suited to handle. Its CUDA platform and Tensor Core architecture provide the acceleration needed for frameworks like PyTorch and TensorFlow, making NVIDIA GPUs the default hardware for training models such as GPT, LLaMA, Claude, and others.
NVIDIA's GPU Lineup¶
NVIDIA's GPU lineup can be categorized into several distinct classes, each tailored to specific computing environments and use cases.
Desktop GPUs (GeForce)
NVIDIA desktop GPUs are primarily designed for consumer PCs and gaming desktops, branded under the GeForce family (e.g.,
RTX 4070,RTX 4090). These GPUs are optimized for high-resolution gaming, ray tracing, and real-time rendering, and they also support GPU-accelerated content creation and AI tasks. With advanced features like DLSS, Reflex, and CUDA support, desktop GPUs offer an excellent balance of performance and affordability for gaming enthusiasts, creators, and hobbyist developers.Mobile GPUs (GeForce Mobile)
NVIDIA mobile GPUs are scaled-down versions of desktop GPUs designed for laptops and ultra-books. Branded similarly (e.g.,
GeForce RTX 4080 Mobile), these chips are power-efficient and thermally optimized to deliver solid gaming and rendering performance on the go. They use technologies like Max-Q to balance power consumption, battery life, and performance—making them ideal for portable gaming and light AI workloads.Workstation GPUs (NVIDIA RTX / Quadro)
Workstation GPUs are professional-grade cards branded under
NVIDIA RTXor formerlyQuadro. These GPUs are designed for CAD, 3D modeling, AI research, data science, and scientific simulations, offering certified drivers and extreme precision (e.g., ECC memory). With larger VRAM, superior FP64 performance, and ISV certification for enterprise software like Autodesk, Adobe, and Siemens, workstation GPUs are built for reliability and accuracy in demanding professional workflows.Console/Handheld GPUs
Console and handheld GPUs are custom-tailored NVIDIA graphics solutions used in platforms like the Nintendo Switch, NVIDIA SHIELD, and some earlier consoles. These chips are often based on Tegra architecture, with integrated GPU cores optimized for portable or embedded gaming. While not as powerful as desktop GPUs, they are designed for efficient thermal performance and long battery life, providing console-grade experiences in mobile form factors.
Data Center GPUs
Data center GPUs are high-performance accelerators used for AI training, LLM inference, HPC, and large-scale simulation tasks. These GPUs are categorized under branding such as
Px,Vx,T4,Ax,Hx, etc. where the leading letter typically denotes the underlying GPU micro-architecture (e.g., Pascal, Volta, Turing, Ampere, Hopper). They deliver massive throughput with features like tensor cores, multi-instance GPUs (MIG), NVLink, and high-bandwidth memory (HBM). They are deployed in server clusters powering cloud services, AI labs, and supercomputers—forming the backbone of modern AI infrastructure. They are used in data centers by companies like OpenAI, Meta, Amazon, and Microsoft Azure.
LLM for Home Users¶
Many home users who own desktop systems equipped with NVIDIA GeForce GPUs—typically used for gaming—can also leverage them for LLM workloads. As of May 2025, the latest flagship consumer GPU is the NVIDIA GeForce RTX 5090, featuring 32 GB of GDDR7 VRAM, which marks a significant leap in both memory capacity and raw computational performance compared to previous generations.
This level of VRAM is more than sufficient for running the majority of quantized LLMs, enabling smooth inference on large models such as LLaMA 3, Mistral, Gemma, and CodeLLaMA. The RTX 5090's support for Tensor Cores, CUDA acceleration, and enhanced memory bandwidth makes it highly capable for not just gaming, but also for running local chatbots, coding assistants, and even fine-tuning smaller LLMs.
Setting up Local LLM¶
Like many technology enthusiasts, I have created a local LLM environment within my home lab. Among the most popular solutions for running LLMs locally are Ollama and LM Studio, each offering distinct advantages. I chose to use Ollama primarily because it is open-source, actively maintained, and provides an easy and efficient interface for running and managing models.
This setup eliminates the need for constant Internet access or reliance on cloud-based inference services. It also allows me to explore various models and parameter sizes in a resource-efficient manner, directly aligned with the capabilities of my local GPU. It’s an ideal environment for testing, fine-tuning, and integrating LLMs into custom applications without incurring the latency or cost associated with cloud-hosted APIs.
You can run Ollama server inside a docker container:
docker run -d --name ollama --gpus all -p 11434:11434 -v ollama:/root/.ollama --restart=always ollama/ollamaOpen an interactive shell to the container:
docker exec -it ollama bashPull a LLM model:
ollama pull llama3:8bAnd then start an interactive chat with it:
ollama run llama3:8bYou'll get a REPL-style shell where you can type prompts and receive responses.
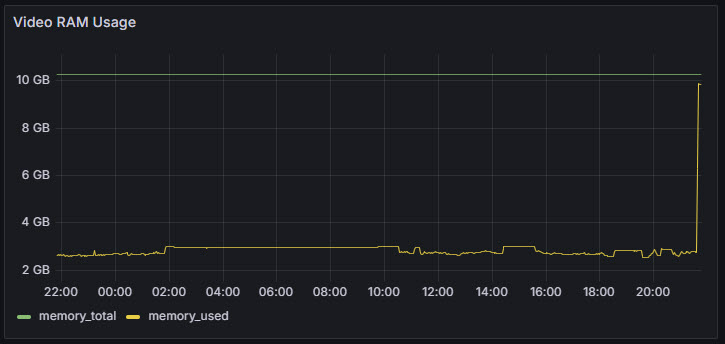
Real-time monitoring of my GPU telemetry confirms that the LLM model is utilizing the GPU rather than the CPU. Key indicators include a significant increase in GPU power consumption (rising to approximately 100 watts), a temperature increase to 60°C, and VRAM usage reaching around 10 GB—all consistent with active GPU inference workloads. Additionally, the elevated load observed on my UPS further supports the conclusion that the system's power draw has increased due to GPU activity.
Ollama Models¶
As of May 2025, Ollama does not provide a public API to retrieve a list of available remote models. To address this limitation, I created the ollama-remote-models project that programmatically scrapes the official Ollama model listing page and extracts detailed information about all supported LLMs.
I have compiled a table listing all currently supported Ollama LLM models. This serves as a valuable reference for anyone looking to explore, compare, or automate the deployment of models from Ollama's ecosystem. The table displays each model along with the parameter sizes it supports, with model names in the first column and parameter sizes as column headers. To enhance usability, the table includes a sticky header and a fixed model name column, ensuring a smooth and user-friendly browsing experience—even when scrolling through large sets of data horizontally or vertically.
| Model | 1m | 22m | 30m | 33m | 110m | 135m | 137m | 278m | 335m | 360m | 567m | 568m | 1b | 2b | 3b | 4b | 5b | 6b | 7b | 8b | 9b | 10b | 11b | 12b | 13b | 14b | 15b | 16b | 20b | 22b | 24b | 27b | 30b | 32b | 33b | 34b | 35b | 40b | 8x7b | 67b | 70b | 72b | 90b | 104b | 110b | 111b | 120b | 123b | 132b | 141b | 8x22b | 180b | 235b | 236b | 405b | 671b |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| alfred | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| all-minilm | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| athene-v2 | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| aya | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| aya-expanse | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| bakllava | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| bespoke-minicheck | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| bge-large | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| bge-m3 | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| codebooga | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| codegeex4 | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| codegemma | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| codellama | ✅ | ✅ | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||
| codeqwen | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| codestral | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| codeup | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| cogito | ✅ | ✅ | ✅ | ✅ | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| command-a | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| command-r | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| command-r-plus | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| command-r7b | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| command-r7b-arabic | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| dbrx | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| deepcoder | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| deepscaler | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| deepseek-coder | ✅ | ✅ | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| deepseek-coder-v2 | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| deepseek-llm | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| deepseek-r1 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||
| deepseek-v2 | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| deepseek-v2.5 | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| deepseek-v3 | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| dolphin-llama3 | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| dolphin-mistral | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| dolphin-mixtral | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| dolphin-phi | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| dolphin3 | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| dolphincoder | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| duckdb-nsql | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| everythinglm | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| exaone-deep | ✅ | ✅ | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| exaone3.5 | ✅ | ✅ | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| falcon | ✅ | ✅ | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| falcon2 | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| falcon3 | ✅ | ✅ | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||
| firefunction-v2 | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| gemma | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| gemma2 | ✅ | ✅ | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| gemma3 | ✅ | ✅ | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||
| glm4 | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| goliath | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| granite-code | ✅ | ✅ | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||
| granite-embedding | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| granite3-dense | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| granite3-guardian | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| granite3-moe | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| granite3.1-dense | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| granite3.1-moe | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| granite3.2 | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| granite3.2-vision | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| granite3.3 | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| hermes3 | ✅ | ✅ | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||
| internlm2 | ✅ | ✅ | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||
| llama-guard3 | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| llama-pro | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| llama2 | ✅ | ✅ | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| llama2-chinese | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| llama2-uncensored | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| llama3 | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| llama3-chatqa | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| llama3-gradient | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| llama3-groq-tool-use | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| llama3.1 | ✅ | ✅ | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| llama3.2 | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| llama3.2-vision | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| llama3.3 | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| llama4 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| llava | ✅ | ✅ | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| llava-llama3 | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| llava-phi3 | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| magicoder | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| marco-o1 | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| mathstral | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| meditron | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| medllama2 | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| megadolphin | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| minicpm-v | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| mistral | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| mistral-large | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| mistral-nemo | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| mistral-openorca | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| mistral-small | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| mistral-small3.1 | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| mistrallite | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| mixtral | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| moondream | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| mxbai-embed-large | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| nemotron | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| nemotron-mini | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| neural-chat | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| nexusraven | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| nomic-embed-text | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| notus | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| notux | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| nous-hermes | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| nous-hermes2 | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| nous-hermes2-mixtral | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| nuextract | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| olmo2 | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| open-orca-platypus2 | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| openchat | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| opencoder | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| openhermes | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| openthinker | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| orca-mini | ✅ | ✅ | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||
| orca2 | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| paraphrase-multilingual | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| phi | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| phi3 | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| phi3.5 | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| phi4 | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| phi4-mini | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| phi4-mini-reasoning | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| phi4-reasoning | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| phind-codellama | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| qwen | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||
| qwen2 | ✅ | ✅ | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| qwen2-math | ✅ | ✅ | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| qwen2.5 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||
| qwen2.5-coder | ✅ | ✅ | ✅ | ✅ | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| qwen2.5vl | ✅ | ✅ | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||
| qwen3 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||
| qwq | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| r1-1776 | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| reader-lm | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| reflection | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| sailor2 | ✅ | ✅ | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| samantha-mistral | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| shieldgemma | ✅ | ✅ | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| smallthinker | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| smollm | ✅ | ✅ | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| smollm2 | ✅ | ✅ | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| snowflake-arctic-embed | ✅ | ✅ | ✅ | ✅ | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||
| snowflake-arctic-embed2 | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| solar | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| solar-pro | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| sqlcoder | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| stable-beluga | ✅ | ✅ | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| stable-code | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| stablelm-zephyr | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| stablelm2 | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| starcoder | ✅ | ✅ | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||
| starcoder2 | ✅ | ✅ | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| starling-lm | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| tinydolphin | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| tinyllama | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| tulu3 | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| vicuna | ✅ | ✅ | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| wizard-math | ✅ | ✅ | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| wizard-vicuna | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| wizard-vicuna-uncensored | ✅ | ✅ | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| wizardcoder | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| wizardlm | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| wizardlm-uncensored | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| wizardlm2 | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| xwinlm | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| yarn-llama2 | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| yarn-mistral | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| yi | ✅ | ✅ | ✅ | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| yi-coder | ✅ | ✅ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| zephyr | ✅ | ✅ |
The following classification groups LLMs by parameter size and resource requirements, specifically in the context of running (inference), not training. Training requires significantly more memory (up to 3× or more).
Tiny
- Parameter Range: 1M – 135M
- VRAM Required: < 1 GB
- Typical Use Case: Lightweight NLP, mobile apps, IoT/edge inferencing
- Hardware Recommendation: CPU-only, Raspberry Pi, microcontrollers
Small
- Parameter Range: 278M – 1B
- VRAM Required: ~1–2 GB
- Typical Use Case: Simple offline chatbots, embedded assistants
- Hardware Recommendation: Integrated GPU or entry-level discrete GPU
Medium
- Parameter Range: 2B – 7B
- VRAM Required: ~4–8 GB (Q4), 12–16 GB (FP16)
- Typical Use Case: General-purpose LLM, summarization, Q&A
- Hardware Recommendation: RTX 3060/4060, Mac M1 Pro/Max, AMD 6800M
Large
- Parameter Range: 8B – 20B
- VRAM Required: ~10–20 GB (Q4), 24–40 GB (FP16)
- Typical Use Case: Code gen, advanced reasoning, creative writing
- Hardware Recommendation: RTX 3080/3090, A5000, Mac M3 Max
Very Large
- Parameter Range: 22B – 70B
- VRAM Required: 24–80 GB
- Typical Use Case: Multi-lingual models, instruction-tuned LLMs
- Hardware Recommendation: A100 80GB, H100 80GB, multi-GPU
Expert Ensemble (MoE)
- Parameter Range: 8x7B, 8x22B
- VRAM Required: 100–200+ GB
- Typical Use Case: Mixture of Experts inference, model routing
- Hardware Recommendation: Multi-node with tensor/model parallelism (DeepSpeed, Megatron)
Huge
- Parameter Range: 90B – 671B
- VRAM Required: 100s of GB to TBs
- Typical Use Case: Cutting-edge research, long-context agents
- Hardware Recommendation: Cloud-only: NVIDIA DGX, Google TPUv5, AWS Trn1 Ultra
LLaMA¶
LLaMA (Large Language Model Meta AI) is a family of open-weight LLMs developed by Meta, designed to advance research and practical deployment of powerful AI models outside of proprietary systems. LLaMA models are auto-regressive transformers trained on publicly available and licensed data, and they come in multiple sizes. Meta has released official LLaMA versions like:
- LLaMA 1 (Feb 2023): 7B–65B
- LLaMA 2 (July 2023): 7B, 13B, 70B
- LLaMA 3 (April 2024): 8B, 70B
- LLaMA 4 (April 2025): Multimodal capabilities
The variants LLaMA 3.1, LLaMA 3.2, and LLaMA 3.3 represent incremental research-driven improvements within the LLaMA 3 family, each building upon the previous model's architecture, training data, or specialization. While LLaMA 3.1 introduced expanded model sizes (including the 405B parameter model), LLaMA 3.2 focused on smaller, efficient variants like 1B and 3B, as well as vision-capable models. LLaMA 3.3 continued this trend by refining the 70B model, achieving performance levels comparable to the much larger 405B model through improved training methods or tuning strategies.
CodeLLaMA is designed specifically for tasks involving code generation, completion, and understanding. It builds upon the LLaMA 2 architecture but is further pre-trained and fine-tuned on high-quality source code across multiple programming languages. CodeLLaMA supports multiple parameter sizes, and includes instruction-tuned variants for chat-based code assistance. By leveraging the strong language understanding of LLaMA 2 and aligning it with structured code data, Meta has positioned CodeLLaMA as a powerful foundation model for developers and researchers working in AI-powered coding tools.
LLaMA-Guard3 is a fine-tuned version of LLaMA 3.1-8B developed by Meta for content safety classification. It can classify content in both prompts and responses, identifying potentially unsafe material.
| Model Name | Parameters | File Size (est.) | Quantization | VRAM Required |
|---|---|---|---|---|
| llama2 | 7b | 3.9 GB | Q4_0 | 6–8 GB |
| llama2 | 13b | 7.2 GB | Q4_0 | 10–12 GB |
| llama2 | 70b | 38.5 GB | Q4_0 | 32–48 GB |
| codellama | 7b | 3.9 GB | Q4_0 | 6–8 GB |
| codellama | 13b | 7.2 GB | Q4_0 | 10–12 GB |
| codellama | 34b | 18.7 GB | Q4_0 | 16–24 GB |
| codellama | 70b | 38.5 GB | Q4_0 | 32–48 GB |
| llama3 | 8b | 4.4 GB | Q4_0 | 10–12 GB |
| llama3 | 70b | 38.5 GB | Q4_0 | 32–48 GB |
| llama3.1 | 8b | 4.4 GB | Q4_K_M | 10–12 GB |
| llama3.1 | 70b | 38.5 GB | Q4_K_M | 32–48 GB |
| llama3.1 | 405b | 222.8 GB | Q4_K_M | 64+ GB |
| llama3.2 | 1b | 0.6 GB | Q8_0 | 4 GB |
| llama3.2 | 3b | 1.7 GB | Q4_K_M | 6–8 GB |
| llama3.2-vision | 11b | 6.1 GB | Q4_K_M | 10–12 GB |
| llama3.2-vision | 90b | 49.5 GB | Q4_K_M | 64+ GB |
| llama3.3 | 70b | 38.5 GB | Q4_K_M | 32–48 GB |
| llama-guard3 | 1b | 0.6 GB | Q8_0 | 4 GB |
| llama-guard3 | 8b | 4.4 GB | Q4_K_M | 10–12 GB |
| llama4 | 109b | 67GB | Q4_K_M | 80–128+ GB |
The growing variety of LLaMA-based models available today reflects both the evolution of Meta’s official releases and the strength of the broader open-source ecosystem. While Meta continues to publish foundational models like LLaMA 2 and LLaMA 3, the community has actively extended these models to suit specific domains, languages, and tasks. These community-driven variants often involve fine-tuning, instruction tuning, or architectural adaptations, enabling broader applicability across research and real-world scenarios. Below is a list of prominent community-developed models based on LLaMA:
| Model Name | Parameters | File Size (est.) | Quantization | VRAM Required |
|---|---|---|---|---|
| tinyllama | 1.1b | 0.6 GB | Q4_0 | 4 GB |
| llama2-chinese | 7b | 3.9 GB | Q4_0 | 6–8 GB |
| llama2-chinese | 13b | 7.2 GB | Q4_0 | 10–12 GB |
| llama3-chatqa | 8b | 4.4 GB | Q4_0 | 10–12 GB |
| llama3-chatqa | 70b | 38.5 GB | Q4_0 | 32–48 GB |
| llava-llama3 | 8b | 5.5 GB | Q4_K_M | 10–12 GB |
| phind-codellama | 34b | 18.7 GB | Q4_0 | 16–24 GB |
| dolphin-llama3 | 8b | 4.4 GB | Q4_0 | 10–12 GB |
| dolphin-llama3 | 70b | 38.5 GB | Q4_0 | 32–48 GB |
| llama2-uncensored | 7b | 3.9 GB | Q4_0 | 6–8 GB |
| llama2-uncensored | 70b | 38.5 GB | Q4_0 | 32–48 GB |
| llama3-gradient | 8b | 4.4 GB | Q4_0 | 10–12 GB |
| llama3-gradient | 70b | 38.5 GB | Q4_0 | 32–48 GB |
| llama3-groq-tool-use | 8b | 4.4 GB | Q4_0 | 10–12 GB |
| llama3-groq-tool-use | 70b | 38.5 GB | Q4_0 | 32–48 GB |
| llama-pro | 8.36B | 4.7GB | Q4_0 | 10–12 GB |
| medllama2 | 7b | 3.9 GB | Q4_0 | 6–8 GB |
| yarn-llama2 | 7b | 3.9 GB | Q4_0 | 6–8 GB |
| yarn-llama2 | 13b | 7.2 GB | Q4_0 | 10–12 GB |
Open WebUI¶
Open WebUI is an open-source, user-friendly web interface designed to interact with LLMs. It provides a chat-based environment that makes it easy for users to run, manage, and communicate with local or remote LLMs through a browser, without needing to write code or use command-line tools. Built with a focus on extensibility and privacy, Open WebUI integrates seamlessly with various model backends, making it ideal for both personal and collaborative AI use cases.
I am running Open WebUI inside a container on my Raspberry Pi node apollo:
docker run -d -p 3000:8080 -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:mainWeb UI will be accessible from:
http://apollo.home:3000/I can then point Open WebUI to the Ollama instance running on my workstation PC. You can check if the Ollama server is up and running using a simple curl request to its health/status endpoint:
curl http://workstation.home:11434
Ollama is runningYou should now be able to view all available LLM models previously pulled by the Ollama server within the Open WebUI interface.
Open WebUI Features¶
Below is a list of Open WebUI features that I find valuable:
Markdown and LaTeX Support
Open WebUI supports rendering of Markdown and LaTeX syntax in responses, enabling rich formatting, including bold/italic text, bullet points, code blocks, tables, and mathematical equations. This is particularly useful in technical domains like education, research, and coding, where readable formatting improves clarity and presentation.
Chat History and Search
This feature stores past conversations for each user, allowing them to revisit previous sessions, continue unfinished discussions, or reference earlier responses. The built-in search functionality helps quickly locate specific prompts or keywords across all saved chats, improving workflow and productivity.
Model Switching
Model Switching allows users to dynamically choose from a list of available LLMs without restarting the session. This makes it easy to compare outputs from different models like llama3, mistral, or gemma, based on task complexity or tone. Users can switch between models in the middle of a conversation to test performance or continue a chat with a different language model.
Multi-Model Chat
This enables users to submit a single prompt to multiple selected models simultaneously and receive parallel responses. The results are displayed side by side for easy comparison, making this feature ideal for evaluating model behavior, accuracy, creativity, or stylistic differences across various LLMs.
Many Models Conversations
Many Models Conversations extend Multi-Model Chat by allowing multiple models to converse with each other autonomously. Models take turns responding to one another, simulating natural dialogue between different AI agents. This feature is valuable for exploring emergent behavior, debate simulation, and collaborative problem-solving among diverse LLMs.
Multi-Modal Model Support
This enables users to interact with advanced language models that can process and understand both text and images within the same conversation. By leveraging models like
LLaVA, this feature allows users to upload images and ask questions about them, such as identifying objects, interpreting visual content, or reading embedded text. It transforms the interface from a purely text-based chatbot into a powerful vision-language assistant.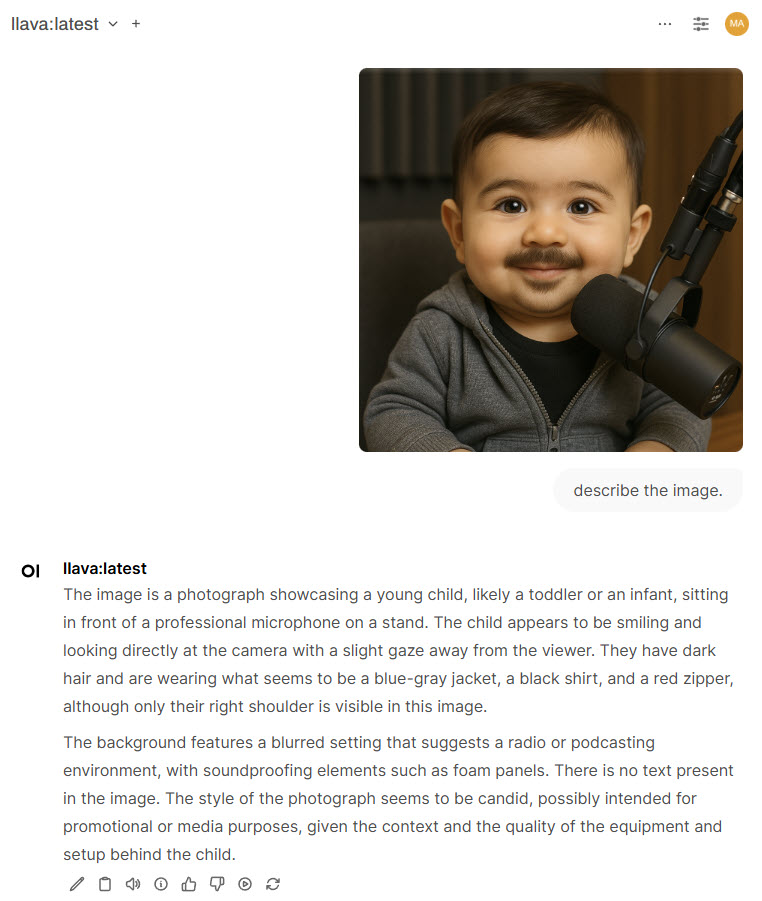
Multi-User Support
Open WebUI supports multiple users with individual accounts, ensuring that each user has access to private settings, chat histories, and model configurations. This is particularly useful in shared or enterprise environments where different users need isolated sessions or customized preferences.
Creating Custom Models
This allows users to define personalized variants of existing base models by specifying system prompt, and optionally a custom avatar. This feature lets users create a tailored version that behaves according to a predefined role or personality—such as a coding assistant, teacher, or creative writer—by setting a default system prompt that influences the model’s responses. These custom models appear in the model list, making it easy to switch between different personas or task-specific configurations without altering the base LLM.
For example, you can create a custom model specifically for your children, with a system prompt that sets boundaries on what the model can and cannot answer directly. Instead of giving away solutions, the model can be configured to encourage critical thinking and provide gentle guidance—helping children learn how to approach and solve problems on their own.
Image Generation Integration
This feature enables users to generate images directly from text prompts by integrating with image generation backends like
Stable Diffusion. Users can switch between text-to-image and text-to-text interactions within the same interface, supporting creative tasks such as illustration, design prototyping, or visual storytelling. To streamline setup, tools like Stability Matrix can be used to install and manage interfaces such as AUTOMATIC1111 or ComfyUI, which can then be integrated with Open WebUI.
Real-time Web Search
This enables the language model to retrieve up-to-date information from the internet during a conversation, bridging the gap between static model knowledge and current events or dynamic data. When this feature is enabled and configured, the model can issue live web queries to answer questions about recent news, stock prices, technology updates, or any topic where real-time accuracy is important. This is particularly useful for tasks that require fresh data beyond the model’s training cutoff, ensuring responses remain relevant and timely. Check this video.
LiteLLM¶
LiteLLM is an open-source LLM API proxy that provides a unified, OpenAI-compatible interface to a wide variety of language model providers such as OpenAI, Azure, Anthropic, Together, Ollama, and more. Its core purpose is to simplify integration across different LLM backends by standardizing API calls. LiteLLM allows developers to switch between providers without changing application logic.
LiteLLM can also be used as a backend for Open WebUI by exposing an OpenAI-compatible API at a local endpoint. Open WebUI can connect to this endpoint by updating its API settings, enabling users to interact with any model configured in LiteLLM. This integration provides a flexible and user-friendly way to test and switch between different LLM providers via a single UI.
Clone the LiteLLM repository:
git clone https://github.com/BerriAI/litellmGo to the root of the repository:
cd litellmCreate an .env file with these two variables (change values accordingly):
LITELLM_MASTER_KEY="sk-1234"
LITELLM_SALT_KEY="sk-XXXXXXXX"Start the LiteLLM container:
docker compose up -dWeb UI will be accessible from:
http://apollo.home:4000/uiBy default, username is admin and password is LITELLM_MASTER_KEY that you had set earlier.
Add LLM models from various providers based on your preferences. For example, my current configuration includes the following models:

Input cost refers to the tokens you send to the model—your prompt, including any system messages, history, or instructions. Output cost is for the tokens generated in the model’s response. These costs are shown in dollars per 1,000 tokens. LiteLLM uses these values to calculate real-time usage costs, enforce budgets, and optimize routing across models. It's important because some models have high output costs, so verbose responses can become significantly more expensive than short ones.
Configure Open WebUI to connect with LiteLLM in order to route requests through a unified API. This allows you to send the same prompt to multiple language models and directly compare their responses side by side within the interface.

LiteLLM Features¶
Below is a list of LiteLLM features that I find valuable:
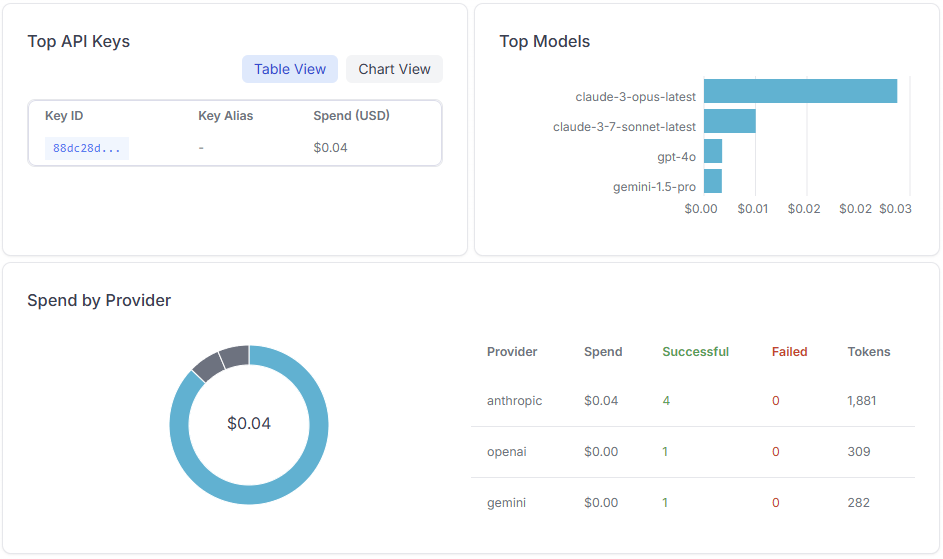
Cost Tracking & Budgets
LiteLLM can track the number of tokens used and calculate real-time cost estimates based on provider pricing. You can define budgets per user, key, or service to prevent runaway costs. This makes it ideal for managing LLM usage in shared, team-based, or customer-facing apps where cost control is critical.
Provider Fallback
LiteLLM supports provider fallback, so if one provider fails (due to rate limits or downtime), it automatically reroutes the request to a backup provider, improving resilience in production environments.
Cost Optimization
By intelligently routing requests based on cost, latency, or success rate, LiteLLM enables cost optimization strategies. For example, it can prefer cheaper providers for certain model types or downscale to smaller models depending on usage patterns, without changing any client code.
Rate Limiting
You can enforce per-user, per-model, or per-key rate limits to ensure fair usage and protect infrastructure. This is helpful when building public APIs or multi-tenant applications using shared LLM capacity, preventing abuse and accidental overload.
Caching
To reduce cost and improve latency, LiteLLM offers response caching based on request similarity. Frequently asked prompts or deterministic completions (e.g., embeddings) can be served instantly from cache instead of invoking the provider repeatedly.
Batch API
LiteLLM supports a Batch API that allows sending multiple prompts in one request, reducing network overhead and improving throughput. This is especially useful for applications that need to process many prompts at once, such as data labeling or chat summarization.
Guardrails
LiteLLM supports custom validation hooks and prompt filters, acting as guardrails for content moderation, input sanitization, and output validation. This is useful for security, compliance, and enforcing business rules before or after an LLM call.
Key Management & Rotation
API keys can be created with scoped permissions, expiration dates, and usage limits. LiteLLM also supports automatic key rotation, allowing you to securely update credentials without downtime or user impact.
S3 Logging
For auditability and analytics, LiteLLM can log requests, responses, costs, and metadata directly to Amazon S3. This makes it easy to integrate with data pipelines, dashboards, or compliance systems for detailed usage reporting.